这两天把minspore配置到我的电脑上了,然后运行就没什么问题了✨😊
今天学这个DCGAN生成漫画头像,我超级感兴趣的嘞🦄🥰
GAN基础原理
这部分原理介绍参考GAN图像生成。

DCGAN原理
DCGAN(深度卷积对抗生成网络,Deep Convolutional Generative Adversarial Networks)是GAN的直接扩展。不同之处在于,DCGAN会分别在判别器和生成器中使用卷积和转置卷积层。
它最早由Radford等人在论文Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks中进行描述。判别器由分层的卷积层、BatchNorm层和LeakyReLU激活层组成。输入是3x64x64的图像,输出是该图像为真图像的概率。生成器则是由转置卷积层、BatchNorm层和ReLU激活层组成。输入是标准正态分布中提取出的隐向量𝑧𝑧,输出是3x64x64的RGB图像。
本教程将使用动漫头像数据集来训练一个生成式对抗网络,接着使用该网络生成动漫头像图片。
数据准备与处理
from download import download
url = "https://download.mindspore.cn/dataset/Faces/faces.zip"
path = download(url, "./faces", kind="zip", replace=True)数据处理
batch_size = 128 # 批量大小
image_size = 64 # 训练图像空间大小
nc = 3 # 图像彩色通道数
nz = 100 # 隐向量的长度
ngf = 64 # 特征图在生成器中的大小
ndf = 64 # 特征图在判别器中的大小
num_epochs = 3 # 训练周期数
lr = 0.0002 # 学习率
beta1 = 0.5 # Adam优化器的beta1超参数
import numpy as np
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
def create_dataset_imagenet(dataset_path):
"""数据加载"""
dataset = ds.ImageFolderDataset(dataset_path,
num_parallel_workers=4,
shuffle=True,
decode=True)
# 数据增强操作
transforms = [
vision.Resize(image_size),
vision.CenterCrop(image_size),
vision.HWC2CHW(),
lambda x: ((x / 255).astype("float32"))
]
# 数据映射操作
dataset = dataset.project('image')
dataset = dataset.map(transforms, 'image')
# 批量操作
dataset = dataset.batch(batch_size)
return dataset
dataset = create_dataset_imagenet('./faces')
import matplotlib.pyplot as plt
def plot_data(data):
# 可视化部分训练数据
plt.figure(figsize=(10, 3), dpi=140)
for i, image in enumerate(data[0][:30], 1):
plt.subplot(3, 10, i)
plt.axis("off")
plt.imshow(image.transpose(1, 2, 0))
plt.show()
sample_data = next(dataset.create_tuple_iterator(output_numpy=True))
plot_data(sample_data)
构造网络
当处理完数据后,就可以来进行网络的搭建了。按照DCGAN论文中的描述,所有模型权重均应从mean为0,sigma为0.02的正态分布中随机初始化。
生成器
生成器G的功能是将隐向量z映射到数据空间。由于数据是图像,这一过程也会创建与真实图像大小相同的 RGB 图像。在实践场景中,该功能是通过一系列Conv2dTranspose转置卷积层来完成的,每个层都与BatchNorm2d层和ReLu激活层配对,输出数据会经过tanh函数,使其返回[-1,1]的数据范围内。
DCGAN论文生成图像如下所示:
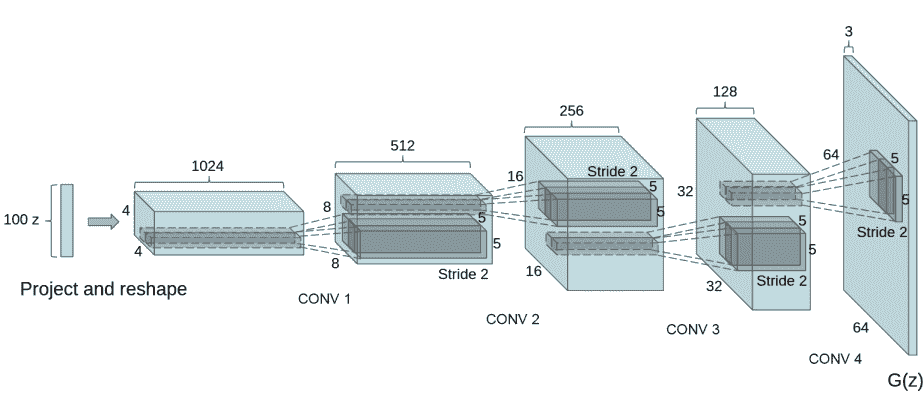
我们通过输入部分中设置的nz、ngf和nc来影响代码中的生成器结构。nz是隐向量z的长度,ngf与通过生成器传播的特征图的大小有关,nc是输出图像中的通道数。
以下是生成器的代码实现:
import mindspore as ms
from mindspore import nn, ops
from mindspore.common.initializer import Normal
weight_init = Normal(mean=0, sigma=0.02)
gamma_init = Normal(mean=1, sigma=0.02)
class Generator(nn.Cell):
"""DCGAN网络生成器"""
def __init__(self):
super(Generator, self).__init__()
self.generator = nn.SequentialCell(
nn.Conv2dTranspose(nz, ngf * 8, 4, 1, 'valid', weight_init=weight_init),
nn.BatchNorm2d(ngf * 8, gamma_init=gamma_init),
nn.ReLU(),
nn.Conv2dTranspose(ngf * 8, ngf * 4, 4, 2, 'pad', 1, weight_init=weight_init),
nn.BatchNorm2d(ngf * 4, gamma_init=gamma_init),
nn.ReLU(),
nn.Conv2dTranspose(ngf * 4, ngf * 2, 4, 2, 'pad', 1, weight_init=weight_init),
nn.BatchNorm2d(ngf * 2, gamma_init=gamma_init),
nn.ReLU(),
nn.Conv2dTranspose(ngf * 2, ngf, 4, 2, 'pad', 1, weight_init=weight_init),
nn.BatchNorm2d(ngf, gamma_init=gamma_init),
nn.ReLU(),
nn.Conv2dTranspose(ngf, nc, 4, 2, 'pad', 1, weight_init=weight_init),
nn.Tanh()
)
def construct(self, x):
return self.generator(x)
generator = Generator()判别器
如前所述,判别器D是一个二分类网络模型,输出判定该图像为真实图的概率。通过一系列的Conv2d、BatchNorm2d和LeakyReLU层对其进行处理,最后通过Sigmoid激活函数得到最终概率。
DCGAN论文提到,使用卷积而不是通过池化来进行下采样是一个好方法,因为它可以让网络学习自己的池化特征。
判别器的代码实现如下:
class Discriminator(nn.Cell):
"""DCGAN网络判别器"""
def __init__(self):
super(Discriminator, self).__init__()
self.discriminator = nn.SequentialCell(
nn.Conv2d(nc, ndf, 4, 2, 'pad', 1, weight_init=weight_init),
nn.LeakyReLU(0.2),
nn.Conv2d(ndf, ndf * 2, 4, 2, 'pad', 1, weight_init=weight_init),
nn.BatchNorm2d(ngf * 2, gamma_init=gamma_init),
nn.LeakyReLU(0.2),
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 'pad', 1, weight_init=weight_init),
nn.BatchNorm2d(ngf * 4, gamma_init=gamma_init),
nn.LeakyReLU(0.2),
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 'pad', 1, weight_init=weight_init),
nn.BatchNorm2d(ngf * 8, gamma_init=gamma_init),
nn.LeakyReLU(0.2),
nn.Conv2d(ndf * 8, 1, 4, 1, 'valid', weight_init=weight_init),
)
self.adv_layer = nn.Sigmoid()
def construct(self, x):
out = self.discriminator(x)
out = out.reshape(out.shape[0], -1)
return self.adv_layer(out)
discriminator = Discriminator()模型训练
损失函数
当定义了D和G后,接下来将使用MindSpore中定义的二进制交叉熵损失函数BCELoss。
优化器
这里设置了两个单独的优化器,一个用于D,另一个用于G。这两个都是lr = 0.0002和beta1 = 0.5的Adam优化器。
训练模型
训练分为两个主要部分:训练判别器和训练生成器。
-
训练判别器
训练判别器的目的是最大程度地提高判别图像真伪的概率。按照Goodfellow的方法,是希望通过提高其随机梯度来更新判别器,所以我们要最大化𝑙𝑜𝑔𝐷(𝑥)+𝑙𝑜𝑔(1−𝐷(𝐺(𝑧))𝑙𝑜𝑔𝐷(𝑥)+𝑙𝑜𝑔(1−𝐷(𝐺(𝑧))的值。
-
训练生成器
如DCGAN论文所述,我们希望通过最小化𝑙𝑜𝑔(1−𝐷(𝐺(𝑧)))𝑙𝑜𝑔(1−𝐷(𝐺(𝑧)))来训练生成器,以产生更好的虚假图像。
在这两个部分中,分别获取训练过程中的损失,并在每个周期结束时进行统计,将fixed_noise批量推送到生成器中,以直观地跟踪G的训练进度。
下面实现模型训练正向逻辑:
# 定义损失函数
adversarial_loss = nn.BCELoss(reduction='mean')
# 为生成器和判别器设置优化器
optimizer_D = nn.Adam(discriminator.trainable_params(), learning_rate=lr, beta1=beta1)
optimizer_G = nn.Adam(generator.trainable_params(), learning_rate=lr, beta1=beta1)
optimizer_G.update_parameters_name('optim_g.')
optimizer_D.update_parameters_name('optim_d.')
def generator_forward(real_imgs, valid):
# 将噪声采样为发生器的输入
z = ops.standard_normal((real_imgs.shape[0], nz, 1, 1))
# 生成一批图像
gen_imgs = generator(z)
# 损失衡量发生器绕过判别器的能力
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
return g_loss, gen_imgs
def discriminator_forward(real_imgs, gen_imgs, valid, fake):
# 衡量鉴别器从生成的样本中对真实样本进行分类的能力
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs), fake)
d_loss = (real_loss + fake_loss) / 2
return d_loss
grad_generator_fn = ms.value_and_grad(generator_forward, None,
optimizer_G.parameters,
has_aux=True)
grad_discriminator_fn = ms.value_and_grad(discriminator_forward, None,
optimizer_D.parameters)
@ms.jit
def train_step(imgs):
valid = ops.ones((imgs.shape[0], 1), mindspore.float32)
fake = ops.zeros((imgs.shape[0], 1), mindspore.float32)
(g_loss, gen_imgs), g_grads = grad_generator_fn(imgs, valid)
optimizer_G(g_grads)
d_loss, d_grads = grad_discriminator_fn(imgs, gen_imgs, valid, fake)
optimizer_D(d_grads)
return g_loss, d_loss, gen_imgs
import mindspore
G_losses = []
D_losses = []
image_list = []
total = dataset.get_dataset_size()
for epoch in range(num_epochs):
generator.set_train()
discriminator.set_train()
# 为每轮训练读入数据
for i, (imgs, ) in enumerate(dataset.create_tuple_iterator()):
g_loss, d_loss, gen_imgs = train_step(imgs)
if i % 100 == 0 or i == total - 1:
# 输出训练记录
print('[%2d/%d][%3d/%d] Loss_D:%7.4f Loss_G:%7.4f' % (
epoch + 1, num_epochs, i + 1, total, d_loss.asnumpy(), g_loss.asnumpy()))
D_losses.append(d_loss.asnumpy())
G_losses.append(g_loss.asnumpy())
# 每个epoch结束后,使用生成器生成一组图片
generator.set_train(False)
fixed_noise = ops.standard_normal((batch_size, nz, 1, 1))
img = generator(fixed_noise)
image_list.append(img.transpose(0, 2, 3, 1).asnumpy())
# 保存网络模型参数为ckpt文件
mindspore.save_checkpoint(generator, "./generator.ckpt")
mindspore.save_checkpoint(discriminator, "./discriminator.ckpt")